Text Coder X for SPSS 1.1 リリースのお知らせ
この度、弊社ではIBM SPSS Statistics上で稼働するテキストコーディング機能アドオン(アドオンとは、ソフトウェアに新たな機能を追加するプログラム)Text Coder X for SPSS の最新バージョン「Text Coder X for SPSS 1.1」を4月10日にリリースいたしました。
IBM SPSS Statisticsのメニューから操作が可能となり、テキストデータを指定しキーワードを抽出することができる本製品に待望の辞書機能が搭載されました。
主なアップデート機能
- 辞書機能
- ストップワード(不要語)に対応
- 100ワードまでの出力から500ワードまでに拡大
- 抽出品詞をファイルで指定可能
- プロジェクトファイルの導入(辞書や品詞指定、savファイルなどを一括管理)
- すべての単語データをファイルに出力できる辞書作成支援
- 単語の切り分け設定が可能に。3段階の調節に対応
稼働環境
- 必須ソフトウェア:IBM SPSS Statistics v29 / v30
- Windows OS:SPSS StatisticsがサポートしているWindows 10/11
- MacOS:SPSS StatisticsがサポートしているMacOS Catalina10.5 / Big Sur11.0 / Monterey12.0 / Ventura13.0 / Sonoma14.0 / Sequoia15.0
- Text Coder X for SPSSは、オープンソースの形態素解析「Sudachi」エンジンを利用して形態素解析を実行しています。
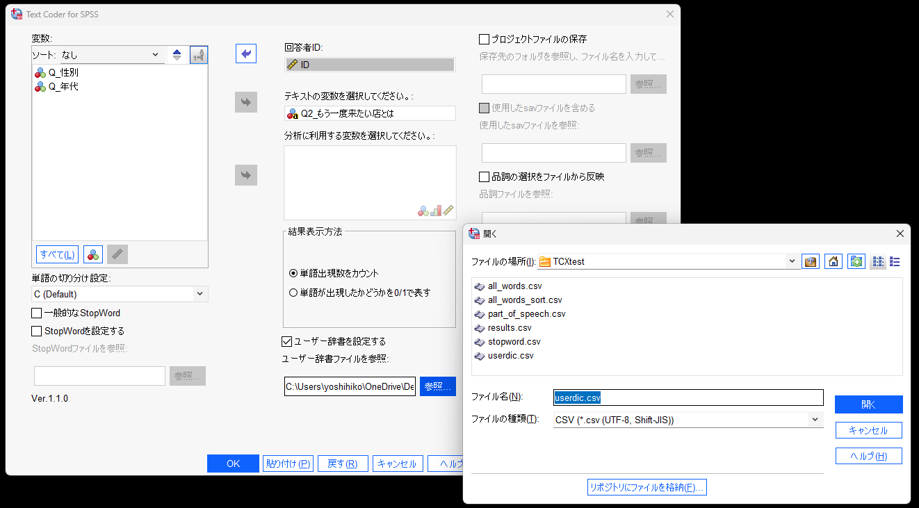
Text Coder X for SPSSのダイアログボックスでユーザー辞書を設定できます。
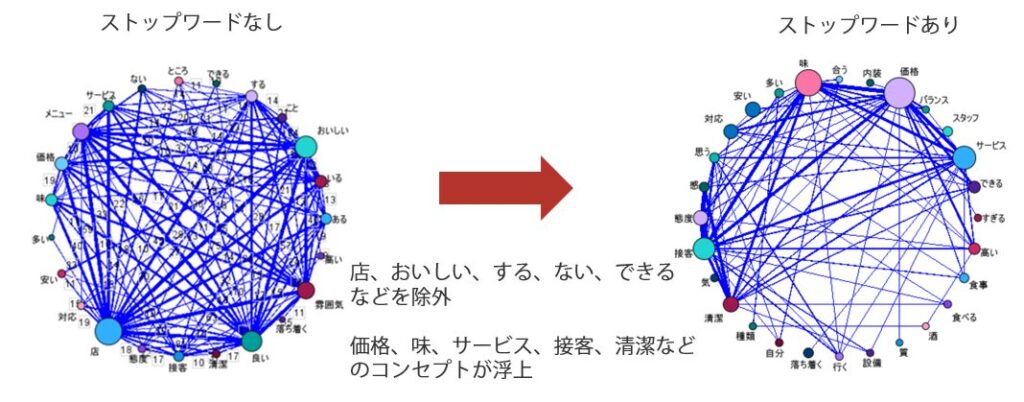
抽出したキーワードを「関連マップ」で確認することで、キーワード同士の関係性を把握することが可能です。
分析に必要ない語(不要語)を分析対象から除外することでコンセプトが浮上します。
