SPSSでt検定(独立・対応あり)を実行する手順|SPSSの使い方 第10回
SPSSでt検定(独立・対応あり)を実行する手順
2つのグループの平均値に差があるか——SPSSでの操作と、結果の読み方を、画面を追いながらいっしょに進めていきましょう。
- 独立サンプルt検定と対応のあるt検定を使い分けられる
- SPSSでt検定を実行できる
- 出力結果のp値・効果量を正しく読める
- 論文・レポートに結果を記述できる
- 2グループの量的データを含むSPSSデータセット
- 独立サンプル:グループ変数1列+検定変数1列
- 対応あり:事前値1列+事後値1列
t検定とは何か(分析手法の位置づけ)
みなさん、こんにちは。スマート・アナリティクスの畠です。このページでは、IBM SPSS Statistics を使って t検定(独立サンプル・対応のある)を実行する手順を、画面を追いながらいっしょに見ていきます。連載「SPSSの使い方」もいよいよ第10回、最終回です。
t検定とは、2つのグループの平均値に統計的な差があるかどうかを検証するための統計手法です。「差があるように見えるけれど、それは偶然ではないと言えるのか?」——その問いに答えるために用います。
本記事は、SPSS をはじめて使う方を対象に、t検定の基本的な考え方から SPSS による実行方法、出力結果の読み方までを「操作と解釈を一体で理解する」ことを目的に書いています。t検定は統計解析のなかでも特に利用頻度が高く、卒業論文・修士論文・学術研究だけでなく、マーケティング施策の効果検証や業務改善の評価など、実務の現場でも広く使われます。たとえば次のような疑問は、t検定で検証できます。
- 男性と女性で満足度の平均に差があるか
- 研修前と研修後でテスト得点は向上したか
- A案とB案で成果指標に違いがあるか
統計解析では「平均値に差があるかどうか」だけでなく、その差が統計的に意味のあるものかを判断することが大切です。t検定は、そのための基本となる分析手法といえます。
ここがポイント
比較するグループが3つ以上のときは、t検定ではなく分散分析(ANOVA)を使います。目的変数が順位尺度・名義尺度のときはノンパラメトリック検定を検討してください。
t検定を使う判断基準と前提条件
t検定は、次の条件を満たす場合に用います。
- 比較したいグループ数が2つ
- 比較対象が量的変数(間隔尺度・比率尺度)
- 平均値の差に着目したい
比較するグループが3つ以上の場合には、t検定ではなく分散分析(ANOVA)を用いるのが一般的です。また、目的変数が順位尺度や名義尺度の場合には、t検定ではなくノンパラメトリック検定を検討します。
さらに、t検定を実行する上では次の前提があることを覚えておきましょう。
t検定を行う前提条件
・標本は無作為に抽出されていること
・母集団の分布が正規分布もしくはそれに近いものであること
・2つのグループの母集団の分散が等しいこと
t検定の種類と使い分け
t検定には、比べる2グループに「対応がある」のか「対応がない」のかによって、主に2種類があります。
| 種類 | 対象 | 例 |
|---|---|---|
| 独立サンプルのt検定 (対応のないt検定) | 互いに独立した2グループ | 男性と女性/A店舗とB店舗/実験群と対照群 |
| 対応のあるt検定 | 同一対象の2時点・2条件 | 施策の実施前と実施後/トレーニング前後/介入前後の測定値 |
独立サンプルのt検定(対応のないt検定)
独立サンプルのt検定は、互いに独立した2つのグループの平均値を比較する手法です。今回はこちらの手法をメインで扱います。各データはどちらか一方のグループにのみ属し、同じ対象が重複して含まれることはありません。
対応のあるt検定
もう一つが「対応のあるt検定」です。これは同一対象に対する2時点・2条件の比較に用います。この場合、個人ごとの差分に着目して平均の変化を検証します。
詳しくは別のコラムで解説するとして、今回は2つのグループを比較する「対応のない2つのグループの差の検定」に焦点を当てて進めていきましょう。平均値の差の検定は、手元のデータ(標本)において2つのグループの平均値に差があった場合、母集団でも同様の差が見られるのか、統計的にその差が意味のあるものなのかを確かめる手法です。たとえば、2つのグループの学生に行ったテストの平均点が異なっていた場合、その差が母集団(全体)でも同様に成り立つのか、点数の差に意味があるのか、それとも偶然なのかを確認するときに利用します。
そのために必要なデータ項目は、グループ(名義)がわかる変数と、平均値を求めるための量的変数の2つです。なお、3つ以上のグループを比較するときは、一元配置分散分析などの手法で行います。
t検定を行う際の前提条件には、無作為抽出のほかに2つあります。1つは2つのグループの両方の分布が正規分布をしていること、もう1つは2つのグループの分散が等分散であることです。この2つの条件をクリアしてはじめてt検定を行うことができます。SPSS Statistics では、正規性についてはt検定を行う前にチェックを行います。等分散性については、等分散性のためのLeveneの検定がt検定の実行と同時に行われ、出力もされます。
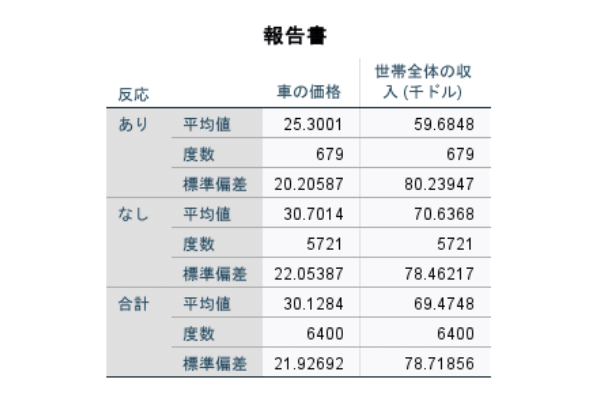
それでは、2つのグループに差があるかどうかを確かめていきましょう。利用するデータは、これまでと同じサンプルデータ[demo.sav]です。今回は、キャンペーンに反応したグループと反応していないグループの2つで、世帯年収に違いがあるのかを確認していきます。
グループの平均で差を見てみる
まずはじめに、検定を行う前に2つのグループで平均値に差があるのかを、基本統計量を使って確認してみることにしましょう。
メニューから[分析]>[平均の比較]>[グループの平均]を選びます。
![グループの平均の比較 ― [分析]>[平均の比較]>[グループの平均]を選択するメニュー操作画面](https://www.smart-analytics.jp/wp-content/uploads/2020/01/t-test-spss-1.png)
[グループの平均]ダイアログが表示されます。[従属変数]の部分に量的変数である[世帯全体の収入(千ドル)]を入れ、[独立変数]部分にはグループを表す変数である[反応]を入れて「OK」を押します。
ポイントは、従属変数部分に量的データ、独立変数にはグループのわかる名義尺度を設定することです。今回はt検定ではなくグループ間の比較を行うため、独立変数部分は2つ以上のグループがあってもかまいません。
![グループの平均の比較の設定 ― [グループの平均]ダイアログで従属変数と独立変数を設定する画面](https://www.smart-analytics.jp/wp-content/uploads/2020/01/t-test-spss-2.png)
出力を見ると、「反応あり」と「なし」で平均値が11(千ドル)ほど違いそうです。2つのグループに差があるように見受けられますが、これが統計的に意味のある差なのかを確認する必要があります。そこで今度は、t検定を使って平均値の差を確かめます。
30分の無料オンライン相談 →
SPSSで独立サンプルのt検定を実行する
平均値に差がありそうだとわかったので、ここからは実際に独立サンプルのt検定を実行していきます。
メニューバーから[分析]>[平均の比較]>[独立したサンプルのt検定]を選びます。前半でも紹介したように、2つのグループの平均値を比較する際には「独立したサンプルのt検定」を選択します。
![SPSSによるt検定の実行 ― [独立したサンプルのt検定]を選択するメニュー操作画面](https://www.smart-analytics.jp/wp-content/uploads/2021/04/t-test-spss-4.png)
[独立したサンプルのt検定]ダイアログボックスが表示されます。左側の変数候補リストから確認したい変数である[世帯全体の収入]を選び、[検定変数]に入れます。[グループ化変数]部分には、2つのカテゴリ値をもつ変数を入れます。ここでは[反応]を入れましょう。
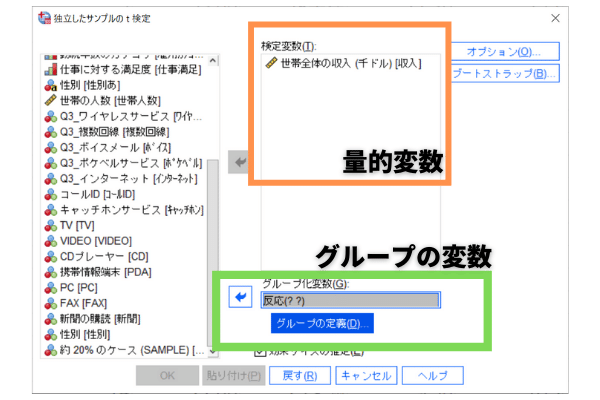
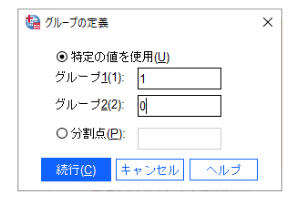
「反応(??)」となっているので、「グループの定義」を押してグループの定義をします。この例では、あり=0、なし=1です。指定したら「続行」を押します。[独立したサンプルのt検定]の画面に戻ると、[グループ化変数]部分が「反応(0,1)」となっているはずです。これでOKです。
ワンポイント
「グループ化変数」が「反応(??)」と表示されるのは、まだグループの値が未定義のサインです。「グループの定義」ボタンから値を指定してくださいね。
出力結果の読み方(等分散性・p値)
SPSSで独立サンプルのt検定を実行すると、出力結果が表示されます。ここからは結果の読み方を順に見ていきましょう。
グループ統計量を確認する
はじめに[グループ統計量]の部分で、各変数の度数や平均値、標準偏差、標準誤差を確認します。確認したうえで、2つのグループの平均値に差があるかを調べるt検定の結果を読んでいきます。
等分散性のためのLeveneの検定を確認する
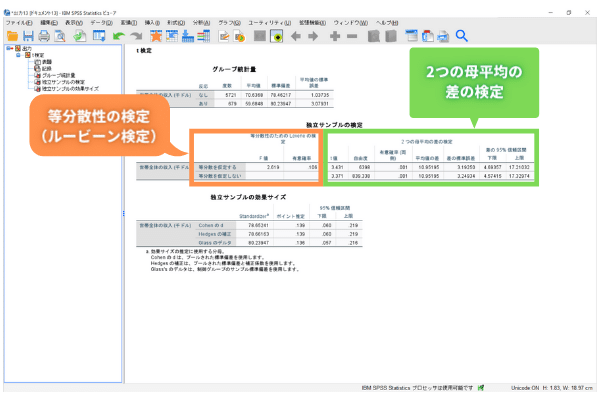
正規性の検定は事前に行っている前提として、このt検定ではまず「2つのグループの母集団の分散が等しい」という等分散性の検定を行います。SPSSの出力でいえば、[独立サンプルの検定]の左側の部分が[等分散性のためのLeveneの検定]に該当します。
この検定の帰無仮説は「2つのグループの分散は等しい」、対立仮説は「2つのグループの分散は等しくない」です。t検定では「2つのグループの母集団の分散が等しいこと」が前提条件なので、ここでは帰無仮説を採用したいところです。通常、検定というと帰無仮説を棄却したい場合が多いのですが、ここは採用する必要があります。
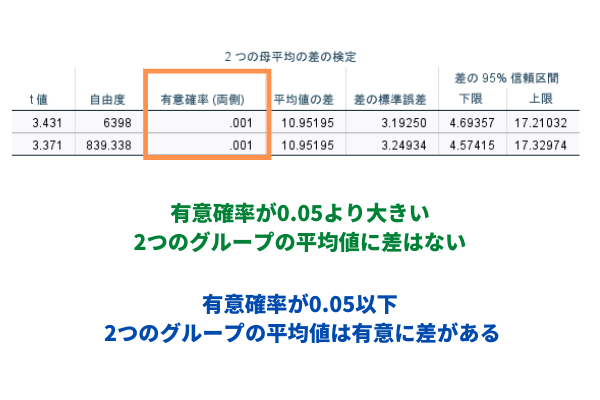
そのため、この部分の[有意確率]が5%(0.05)を超える場合には、そのまま右側の[2つの母平均の差の検定]に進み、[有意確率(両側)]部分を確認します。今回の結果の場合、[有意確率]が0.106、つまり10.6%です。このため、等分散を仮定していると解釈できるので、[等分散を仮定する]行を確認します。[等分散性のためのLeveneの検定]の有意確率部分が5%に満たない場合には、[等分散を仮定しない]行に進み、右側の[2つの母平均の差の検定]を確認します。

2つの母平均の差の検定を確認する
右側に移動し、[2つの母平均の差の検定]の[有意確率(両側)]を確認します。今回は0.001となっていますので、その差は母集団においても同様にあるといえ、統計的に有意であると解釈できます。したがって、ダイレクトメールの反応「あり」「なし」の2つのグループで世帯収入に差があるということがわかります。
平均値の差の検定では、Leveneの検定の部分の解釈が若干ややこしいともいえますので、注意して分析を進めてください。
気をつけたいこと
「統計的に有意である」という結論が、差の“原因”を特定したわけではない点に注意してください。t検定はあくまで「平均値の差が偶然かどうか」を判断する手法であり、なぜその差が生じたのか、どの要因が影響しているのかを直接示すものではありません。
結果の解釈・効果量・よくある誤解
t検定の結果を文章で説明する
SPSSの出力を見て「有意だった」「有意でなかった」で終わってしまうのは、統計分析としては不十分です。重要なのは、その結果を第三者に伝わる形で説明できるかどうかです。たとえば今回の分析結果は、次のように文章化できます。
記述例
ダイレクトメールへの反応の有無によって世帯収入の平均値を比較した結果、両群の平均値には統計的に有意な差が認められた(t検定、p < .01)。
このように、「何を比較し」「どの検定を用い」「どの水準で有意だったのか」を簡潔にまとめることが重要です。
有意差があっても「差が大きい」とは限らない
t検定では有意確率(p値)によって差の有無を判断しますが、p値は差の大きさを示す指標ではありません。サンプルサイズが大きい場合、実務的にはほとんど意味のない差であっても統計的に有意になることがあります。そのため近年では、p値とあわせて効果量を確認することが強く推奨されています。
効果量は、平均値の差がどの程度大きいのかを定量的に示す指標です。独立サンプルのt検定では、代表的な効果量としてCohen's dが用いられます。一般的な目安として、Cohen's d は以下のように解釈されます。
| Cohen's d の値 | 効果の大きさ |
|---|---|
| 0.2 程度 | 効果が小さい |
| 0.5 程度 | 効果が中程度 |
| 0.8 以上 | 効果が大きい |
研究や実務では、「統計的に有意かどうか」だけでなく、その差が実務的・理論的に意味のある大きさかを、効果量を用いて判断することが重要です。
t検定でよくある誤解と注意点
- t検定を何度も繰り返して多群比較をしてしまう
- 等分散性の検定結果を見ずに結果を解釈してしまう
- 「有意差が出た=原因が特定できた」と考えてしまう
- サンプルサイズの影響を考慮しない
これらはいずれも、SPSSを使い始めたばかりの方が陥りやすいポイントです。分析手法の前提条件と結果の意味を正しく理解することで、こうした誤りは防ぐことができます。
次に学ぶべき分析手法
t検定は2群比較に特化した分析手法です。比較するグループが3つ以上ある場合や、他の要因を統制しながら差を検証したい場合には、別の分析手法を用いる必要があります。分散分析(ANOVA)、共分散分析(ANCOVA)、回帰分析などについても、今後の「SPSSの使い方」シリーズで順に解説していきます。
SPSSによるt検定でよくある質問
関連リンク・あわせて読みたいページ
わからないところは、いっしょに。
「自分のデータでどう使えばいい?」「卒論のこの部分が不安」——どんな小さなことでも大丈夫です。IBM公式プラチナパートナーとして、研究・実務のあらゆる段階をお手伝いします。

